National Ethics Advisory Committee
Kāhui Matatika o te Motu
The increase of digital data collection and computational speed has facilitated the rapid development of analytical tools and techniques to gain additional insight from data. Statistical analysis, machine learning, and artificial intelligence are terms used to describe a spectrum of analytic techniques that range from traditional statistical analysis through to evolving approaches such as deep learning.
However, for the purposes of this document ‘artificial intelligence’ (AI) will be used to encompass approaches that are algorithmically-driven. This definition is intentionally broad as AI is often used as an umbrella term to refer to a number of techniques, encompassing everything from machine learning and natural language processing to expert systems and vision. In these Standards, the term ‘AI’ covers all these techniques.
AI is a rapidly evolving science, and the application of AI in healthcare has the potential to significantly transform healthcare delivery at all steps of the patient journey. Potential or realised applications would cover prediction of illness in the presently well individual through diagnosis to death, and will touch on all aspects of population health, system planning, service delivery, and individual medical specialities.
While offering great opportunity, these emerging technologies present defined and presently undefined risks, and the evolving science of AI presents difficulty in outlining explicit ethical standards. Therefore, this section will first frame the general principles guiding the ethics of biomedicine as they apply to AI, then frame standards applying these principles to specific circumstances. All researchers employing health data in AI systems throughout the AI life cycle as outlined in Figure 13.1 should refer to the ethical principles described below in the absence of a standard that directly applies to their case. The standards in this chapter are also likely to be updated periodically. Researchers are encouraged to check for updates prior to submitting applications which involve the use of AI for ethical review.
Figure 13.1 – The AI life cycle
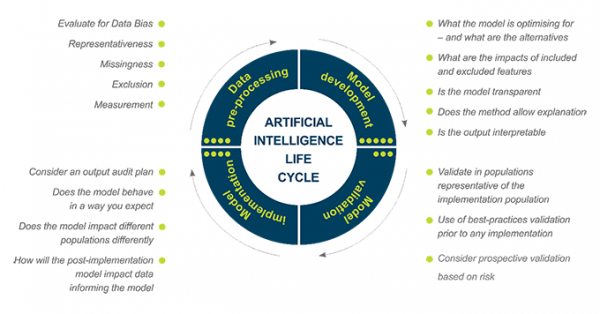
An AI project can be broken down into series of interdependent steps:
Not all AI projects will touch on all elements of this life cycle.
Given the breadth of situations to which AI is being applied, the emerging use of AI systems in healthcare raises a number of potential ethical challenges. Other jurisdictions have highlighted that AI interfaces with the themes of consent, autonomy, privacy, fairness, bias, justice, transparency, reliability, accountability and liability (Nuffield Council on Bioethics 2018; Fenech et al 2018). As healthcare systems and healthcare delivery increasingly become supported by, integrated with, or delegated to AI systems it is critical that they are in line with the fundamental societal values that shape healthcare delivery and research ethics as well as individual rights. Ethical reflection about AI should be grounded on the ethical principles and concepts applicable to health data generally.
Certain aspects of AI development create unique difficulties in foreseeing the impact of the technology on some of these principles. The concepts around algorithmic transparency, interpretability, and explainability are presently evolving – leading to so-called ‘black-box’ problems, where the impact of any specific data structure or element on the final algorithmic output is obscured by the methodology itself. The above principles can still be applied in this circumstance, but may not be applicable by design, only by transparency of the impact of AI implementation in the broader biomedical and societal context.
13.1 While the state of AI does not guarantee built-in explainability, researchers must ensure that the processes, capabilities, purpose, and impact must be transparent and evaluable.
Data is used to develop the algorithms supporting AI, and in self-learning approaches is used in implementation. This data may be from traditional healthcare domains, such as clinical activities in healthcare environments, data generated explicitly or as a by-product of screening, diagnosis, and treatment. This may include demographics, medical notes, electronic recordings from medical devices, data from physical examinations and clinical laboratory data, imaging and genetic testing (Jiang et al. 2017). AI systems may merge these health data sources with non-health data, such as social media, locational data, and socio-economic data.
13.2 While individual datasets may be non-identifiable, as data sets are merged, AI researchers should be conscious that methodologies presently allow identification of even non-identified data contributors if the dataset is sufficiently linked with a high degree of accuracy.
13.3 Researchers of AI need to carefully consider the nature of the data, as well as the people who are accessing and using the data.
13.4 Researchers must carefully consider the risk of harm the use of AI may cause to participants.
A useful framework for risk categorisation has been developed by the International Medical Device Regulators Forum (IMDRF) for Software used as a Medical Device (SaMD)(external link). According to the SaMD risk framework, consideration should be given to the following two major factors which help to describe the intended use of the AI which, in turn, helps to inform the risk its outputs may have on participants:
| State of healthcare situation or condition | Significance of information provided by SaMD to healthcare decision | ||
|---|---|---|---|
| Treat or diagnose | Drive clinical management | Inform clinical management | |
| Critical | IV | III | II |
| Serious | III | II | I |
| Non-serious | II | I | I |
After determining the significance of (1) the information provided by the AI to the healthcare decision, and (2) the state of the healthcare situation or condition for which the AI is intended to be used, Table 13.1 SaMD risk matrix provides guidance on the levels of impact the AI may have on participants.
The four categories (I, II, III, IV) are in relative significance to each other; Category IV has the highest level of impact while Category I has the lowest impact.[2]
These standards apply to data used for pre-processing, model development and validation and implementation of AI.
13.5 Researchers must ensure that the intended use of AI is fair and is intended to benefit New Zealanders (Stats NZ and Privacy Commissioner 2018). They must identify the risks and benefits of the AI system, paying particular attention to ensuring it does not contribute to inequalities, for example by negatively discriminating against classes of individuals or groups.
13.6 Researchers must be mindful of the need to consult with Māori as partners, and of the need to consult with all relevant researchers to ensure they manage data use involving AI systems in a trustworthy, inclusive and protected way (Stats NZ and Privacy Commissioner 2018).
13.6.a Consultation is especially important if the research is a partnership between private and public organisations. In this case, researchers must clearly identify the aims and goals of each contributing partner, together with information about who will have access to what data and for what purposes, and who is accountable.
13.7 Intended use of AI should be explained in language that is clear, simple and easy to understand to those not directly involved in the AI lifecycle.
13.8 The source of the data, particularly with regards to quality, completeness, representativeness, and risk of bias, should be evaluated.
13.8.a Design and the implementation of measures to correct and mitigate risks arising from data bias should be considered.
13.9 The data should be evaluated with regards to identifiability and risk of re-identification.
13.10 Data used in an AI life cycle must be safeguarded with both data security and integration of appropriate levels of security into data storage and each element of the AI life cycle, including against adversarial attacks.
13.11 Data used in AI should have a plan for storage, reuse, destruction or retention, and should have effective and robust data management plans in place.
13.12 Project-specific data governance policies and procedures should adhere to local, organisational, regional, and national data governance requirements.
13.13 Researchers must be transparent about methodologies used in the AI life cycle. There should be justification for a specific method, an accounting for the specific risks and limitations of the methodology, and the consideration of alternative approaches.
13.14 Model development and choices of methodology should be clear in their optimisation parameters and explainability of input and output to model.
13.15 AI implemented in live environments are strongly encouraged to have a monitoring and audit plan in place to assess issues of safety, accuracy, bias and fairness.
13.15.a Insight into the drivers of AI output is at times limited by the methodology itself – concepts such as black-box algorithms, explainability, and transparency are set against issues such as fairness and bias. However, such approaches do not remove ethical accountability from the researchers. Current approaches to accessing and evaluating risk in this setting recommend ongoing audit of input and output.
13.15.b Measures to mitigate risks arising in safety, accuracy, bias and fairness resulting from the application of AI should be in place prior to implementation.
13.15.c Algorithms should be transparent about the involvement of automated input-output loops versus human-in-the-loop designs. Provision for human input and oversight should be integrated into design or implementation governance structures. If there is no such provision, this absence must be justified.
13.16 Researchers must clearly identify who is accountable for each step of the AI life cycle, and how they are accountable.
13.16.a Accountability in this context references both accountability for algorithmic behaviour/output, and accountability for subsequent actions based on the algorithm. Clear lines of accountability for addressing safety, accuracy, bias and fairness involving the AI should be in place prior to any deployment/ implementation.
13.17 Prior to data pre-processing, model development and validation, researchers using AI should account for the following:
13.18 Prior to implementation, researchers using AI should account for the following:
[1] Further descriptions and examples of these decisions, situations and conditions may be found at "Software as a Medical Device": Possible Framework for Risk Categorization and Corresponding Considerations(external link).
[2] Further explanations of this matrix may be found at "Software as a Medical Device": Possible Framework for Risk Categorization and Corresponding Considerations(external link).
